知识图谱在金融领域的应用
摘要
知识图谱旨在对现实世界中的实体或概念及其之间的关系进行建模,是一种新的海量数据组织、管理和利用方式。自2012年谷歌推出知识图谱以来,它在学术界和工业界掀起了一股热潮,已经在许多领域扮演着重要角色。本文重点关注知识图谱在金融领域的应用,首先从知识图谱是什么(What),为什么要构建知识图谱(Why),怎样构建知识图谱(How)的逻辑出发,介绍知识图谱的技术背景;然后对知识图谱的金融应用场景(Where)加以探讨和展望。
关键词: 知识图谱 金融 应用
1. 知识图谱是什么(What)
知识图谱(Knowledge Graph)的提出是为了描述现实世界中的实体、概念以及它们之间的关联。它本质上是一个语义网络,是基于图的数据结构,由节点和边组成。
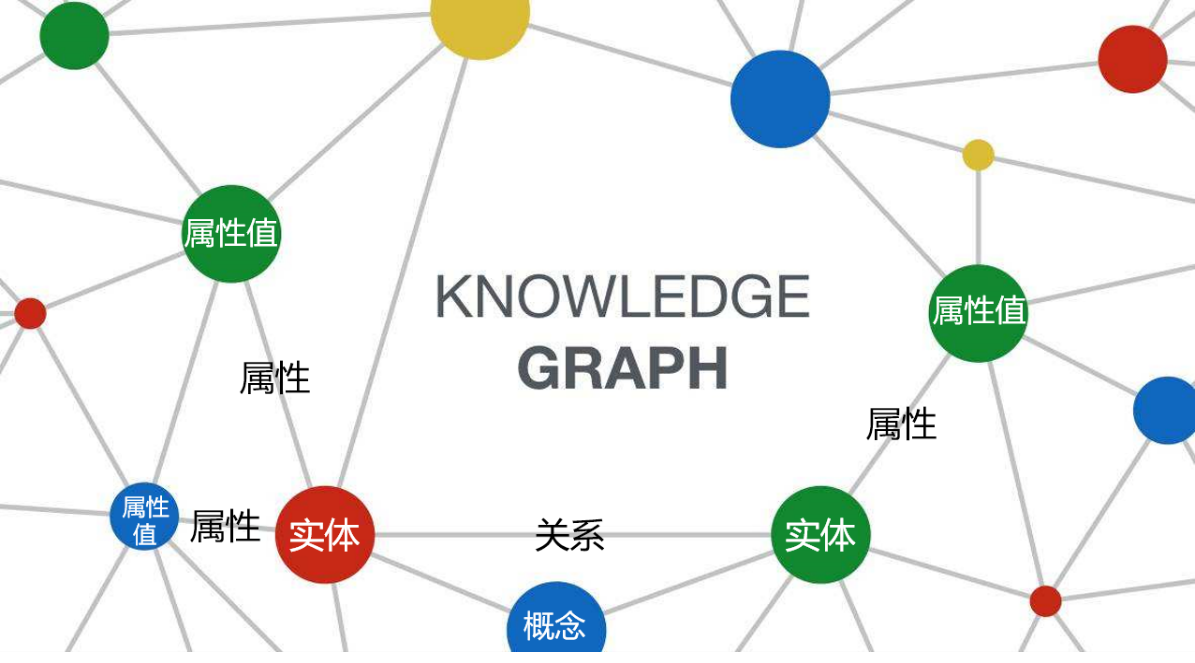
如上图所示,知识图谱的基本形式为<实体1, 关系, 实体2>、<实体, 属性, 属性值>。其中,节点表示实体、概念或属性值;边表示关系或属性。下面分别对实体、概念、属性、属性值、关系的含义进行阐释说明:
-
实体:实体是知识图谱中最基本的元素,指的是具有可区别性且独立存在的某种事物。如某一个人:Barack Obama、姚明等;某一个国家:中国、英国等;某一座城市:北京、纽约等。即现实世界由实体组成。
-
概念:指对具有相同特性的实体的概括和抽象,如国家、城市、民族等。
-
属性:用于区分概念的特征,不同概念具有不同的属性。如城市对应的属性有:面积、人口等。
-
属性值:实体指向的属性的值。例如:“中国的面积为960万平方公里”,其中“中国”为实体,“面积”为属性,“960万平方公里”为属性值。
-
关系:关系是实体或概念之间的关联,如:路遥与《平凡的世界》之间存在着创作关系。关系可以看作是一种特殊的属性,当属性值对应的是概念或实体时,属性就等价于关系。
基于上述基本概念,我们对知识图谱有了初步的认知,下面本节将依次介绍知识图谱的组成结构、表示方法、分类以及发展历程。
1.1 组成结构
与传统的数据库相似,知识图谱同样可分为模式层和实例层;但与关系型数据库的ER模型不同的是,知识图谱的模式层一般称为本体层(Ontology)。如下图,“Barack Obama”与“New York City”等节点是实例层的实体,“Politician”与“City”等节点是它们对应的本体层的概念。位于箭头旁的“was_born_in”、“leader”等则表示关系。
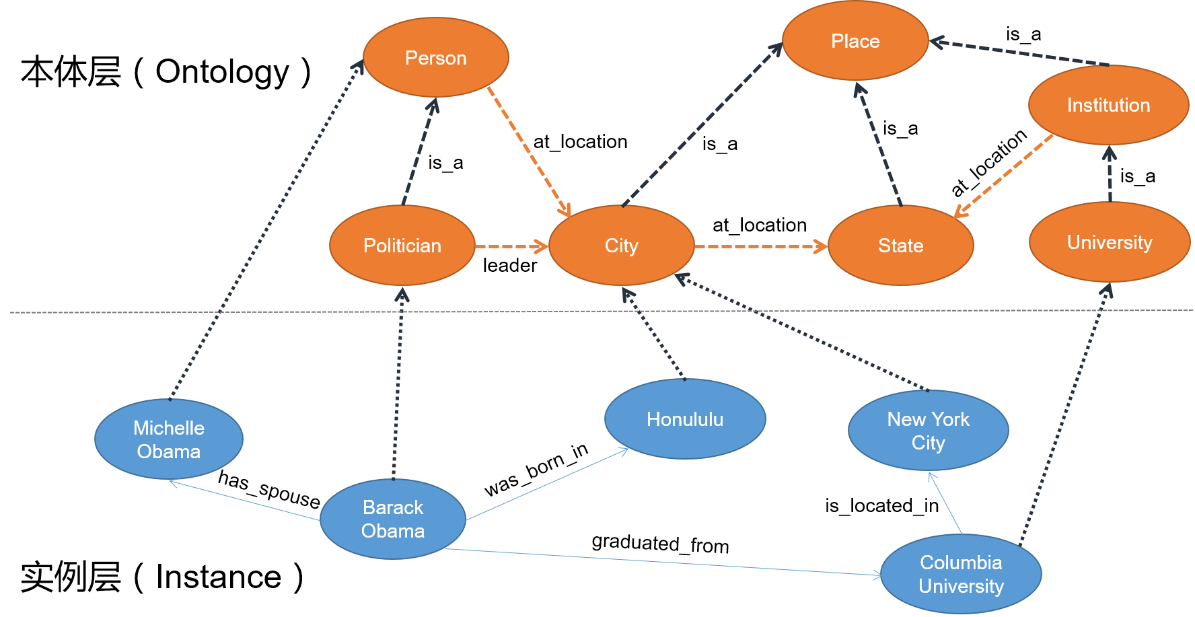
可以看出:不仅实例层的节点之间存在关系,本体层的节点之间也存在关系。另外,与普通的图不同的是,知识图谱中包含多种类型的节点和边,因此知识图谱又可看作是一种异质信息网络。
1.2 表示方法
知识图谱的表示方法一般可分为两类:基于符号的表示和基于向量的表示。
1.2.1 基于符号的表示
基于符号的表示有RDF、RDFS、OWL等。
RDF(Resource Description Framework)本质是一个基于有向标记图(Directed Labeled Graph)的数据模型,它提供了一个统一的标准,用于描述实体(资源)。RDF形式上表示为SPO三元组,即(Subject-主语, Predicate-谓语, Object-宾语)。一个SPO三元组对应一个逻辑表达式或关于现实世界的陈述,可以理解为:Subject表示头实体,Predicate表示关系,Object表示尾实体。
RDF的表达能力有限,无法区分类(Class)和对象(Object),也无法定义描述类的属性以及类间的关系,因此W3C又制定了RDFS和OWL标准。
RDFS(Resource Description Framework Schema)是一种基础的模式语言,它在RDF的基础上扩展了本体的表达。RDFS主要包括如下元语:Class, subClassOf, type, Property, subPropertyOf, Domain, Range等。基于这些简单的表达构件可以构建最基本的类层次体系和属性体系。
OWL(Web Ontology Language)在RDFS的基础上又增加了预定义的词汇,进一步扩展了表示类和属性约束的表示能力,可以构建更为复杂而完备的本体。这些扩展的本体表达能力包括:
-
复杂类表达(Complex Classes),如:intersection, union, complement等;
-
属性约束(Property Restrictions),如:existential quantification, universal quantification, hasValue等;
-
基数约束(Cardinality Restrictions),如:maxQualifiedCardinality, minQualifiedCardinality, qualifiedCardinality等;
-
属性特征(Property Characteristics),如:inverseOf, SymmetricProperty, AsymmetricProperty, propertyDisjointWith, ReflexiveProperty, FunctionalProperty等。
上述基于符号的表示易于刻画显性、离散的知识,因而具有内生的可解释性。但由于人类知识还包含大量不易于符号化的隐性知识,完全基于符号逻辑的知识表示通常由于知识的不完备而失去鲁棒性,特别是推理很难达到实用。由此催生了采用连续向量方式表示知识的研究。
1.2.2 基于向量的表示
基于向量的表示有组合模型、神经网络模型、转换模型等。
组合(Composition)模型将知识图谱建模为三维邻接张量,又被称为“张量分解”(tensor factorization)模型。其典型特征是将实体建模为列向量、关系建模为矩阵,然后通过头实体向量与关系矩阵的线性组合,再与尾实体进行点积计算打分函数。例如采用普通矩阵的RESCAL3、采用低秩矩阵的LFM4等。
神经网络(Neural Network)模型通过非线性计算对实体-关系交互进行建模,如采用单层非线性网络的SLM、NTN5等。
转换(Translation)模型的灵感来自word2vec中词汇关系的平移不变性。它将关系建模为转换(translation)操作,即将关系看作是头实体到尾实体的转换,认为经过向量化的头实体\(\mathbf{h}\)、关系\(\mathbf{r}\)和尾实体\(\mathbf{t}\)满足:\(\mathbf{h}\mathbf{+ r \approx t}\),如基于向量的三角形法则和范数原理的TransE6、通过超平面转化处理多元关系的TransH7等。
这种基于向量的知识表示可以通过数值运算发现新事实和新关系,并能更有效地发现更多的隐性知识和潜在假设,这些隐性知识通常是人的主观不易于观察和总结出来的。更为重要的是,知识图谱嵌入也通常作为一种辅助的先验知识输入到很多深度神经网络模型中,用来约束和监督神经网络的训练过程。
1.3 分类
知识图谱的分类方式很多,分类依据可以是知识种类、构建方法等。从所涉领域的角度出发,知识图谱通常可分为通用领域知识图谱(Open Domain)和特定领域知识图谱(Specific Domain)两类。
通用领域知识图谱可以看作是一个面向通用领域的结构化的百科知识库,其中包含了大量的现实世界中的常识性知识,覆盖面广,如Freebase8、YAGO9、WikiData10、DBPedia11、Nell12、Probase13和谷歌的Knowledge Vault14等。
特定领域知识图谱可以看作是一个基于语义技术的行业知识库,因其基于行业数据构建,有着严格而丰富的数据模式,对领域知识的深度、知识准确性要求高,如生命科学领域的Bio2RDF15和Gene Ontology16,以及描述家谱关系的Kinship17等。
1.4 发展历程
知识图谱属于人工智能重要研究领域——知识工程的一个分支。为了更好地了解知识图谱的理论基础,下面我们回顾一下知识工程的发展历程。如下图,知识工程的发展历程可分成五个标志性的阶段:前知识工程时期、专家系统时期、万维网时期,群体智能时期以及知识图谱时期12。
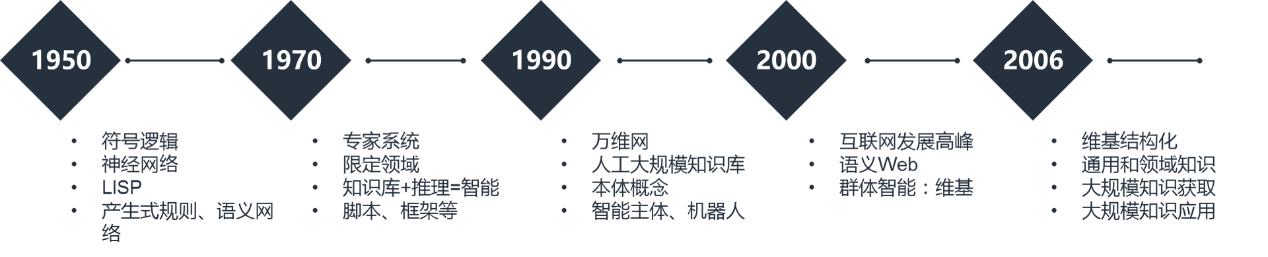
- 1950-1970年代:前知识工程时期
前知识工程时期使用图灵测试作为评测智能的手段。这一时期人们对人工智能的理解主要可分为两个学派:符号主义和连结主义。符号主义认为物理符号系统是智能行为的充要条件;连结主义则认为大脑(大脑神经元及其连接机制)是一切智能活动的基础。这一时期具有代表性的工作是通用问题求解程序(GPS):首先将问题进行形式化表达,然后通过搜索,从问题初始状态,结合规则或表示得到目标状态。其中比较成功的应用是博弈论和机器定理证明等。这一时期的知识表示方法主要有逻辑知识表示、产生式规则、语义网络等。人工智能和知识工程的先驱Minsky,Mccarthy,Newell和Simon四位学者因为在感知机、人工智能语言、通用问题求解和形式化语言方面的杰出工作分别获得了1969年、1971年、1975年的图灵奖。
- 1970-1990年代:专家系统时期
通用问题求解强调利用人的求解问题的能力建立智能系统,而忽略了知识对智能的支持,使人工智能难以在实际应用中发挥作用。1970年开始,人工智能开始转向建立基于知识的系统,通过“知识库+推理机”实现智能,这一时期涌现出很多成功的限定领域专家系统,如MYCIN医疗诊断专家系统、识别分子结构的DENRAL专家系统、以及计算机故障诊断XCON专家系统等。1994年图灵奖获得者Feigenbaum在70年代提出知识工程的定义,从此确立了知识工程在人工智能中的核心地位。这一时期知识表示方法有新的演进,包括框架和脚本等。80年代后期出现很多专家系统的开发平台,可以帮助将专家的领域知识转变成计算机可以处理的知识。
- 1990-2000年代:万维网时期(Web 1.0)
在1990-2000年间,出现了很多人工构建的大规模知识库,包括英文的WordNet、采用一阶谓词逻辑知识表示的Cyc常识知识库、以及中文的Hownet。万维网的产生为人们提供了一个开放平台,它使用HTML定义文本的内容,通过超链接把文本连接起来,使得大众可以共享信息。W3C提出的可扩展标记语言XML,通过定义标签对互联网文档内容的结构进行标记,为互联网环境下大规模的知识表示和共享奠定了基础。这一时期还提出了本体的知识表示方法。
- 2000-2006年代:群体智能时期(Web 2.0)
在2001年,万维网发明人、2016年图灵奖获得者Tim Berners-Lee提出语义Web的概念,旨在对互联网内容进行结构化语义表示。W3C进一步提出互联网语义标识语言RDF(资源描述框架)和OWL(万维网本体表述语言),利用本体描述互联网内容的语义结构,通过对网页进行语义标识得到网页语义信息,使人和机器能够更好地协同工作。
万维网的出现使得互联网上的知识由封闭走向开放,由集中变为分布。原来专家系统是系统内部定义的知识,现在可以实现知识源之间相互链接,可以通过关联来产生更多的知识,而非完全由固定人生产。这个过程中出现了群体智能,最典型的代表就是维基百科,实际上是用户去建立知识,体现了互联网大众用户对知识的贡献,成为今天大规模结构化知识图谱的重要基础。
- 2006年至今:知识图谱时期
从2006年开始,大规模维基百科类富结构知识资源的出现和网络信息提取方法的进步,使得大规模知识获取方法取得了巨大进展。与Cyc、WordNet和HowNet等手工研制的知识库不同,这一时期知识获取是自动化的,并且在网络规模下运行。最具代表性的大规模网络知识获取的工作包括Freebase、YAGO、WikiData、DBPedia、Nell、Probase等。
除了这些通用领域的应用,知识图谱逐渐扩展到限定领域。典型的例子是谷歌收购Freebase后在2012年推出的语义搜索产品,IBM的Watson深度问答系统,以及商业、金融、生命科学等特定领域的知识库。此外,知识图谱的应用还包括大数据语义分析、智能知识服务等。更多知识图谱的创新应用还有待开发。
2. 为什么构建知识图谱(Why)
上文介绍了什么是知识图谱,那么为什么要构建知识图谱呢?整体而言,知识图谱是大数据时代应运而生的一种技术手段。相较数据库时代,大数据时代的数据性质和数据模式都发生了巨大的变化。
在数据性质方面,数据库时代的数据规模较小,类型较单一,且通常是结构化数据;而大数据时代的数据量较大,类型较丰富,不仅包含结构化的数据,还包含半结构化,甚至非结构化的数据。
在数据模式方面,数据库时代的数据模式相对固定,一般可以预先确定,即先有数据模式后产生数据;而大数据时代的数据模式随着数据增长不断演变,难以预先确定。
由于这些差异,大数据时代面临着众多挑战,而知识图谱则提供了应对这些挑战的一种方式。
第一,针对多源异构数据难以融合的挑战,使用知识图谱进行抽象建模,基于可动态变化的“概念-实体-属性-关系”数据模型,可以实现各类数据的统一建模。
第二,针对数据模式动态变迁困难的挑战,知识图谱基于图模型的数据存储,便于数据模式的动态变化。
第三,针对分散的数据难以统一利用的挑战,知识图谱在知识融合的基础上,基于语义检索、智能问答、图计算、推理、可视化等技术,可以提供统一的数据检索、分析和利用平台。
3. 怎样构建知识图谱(How)
本节首先介绍知识图谱的构建流程,然后对其中的技术要点做进一步展开说明。
3.1 构建流程
如下图所示,知识图谱的构建流程可分为知识建模、知识获取、知识融合、知识存储/计算、以及知识应用五阶段。
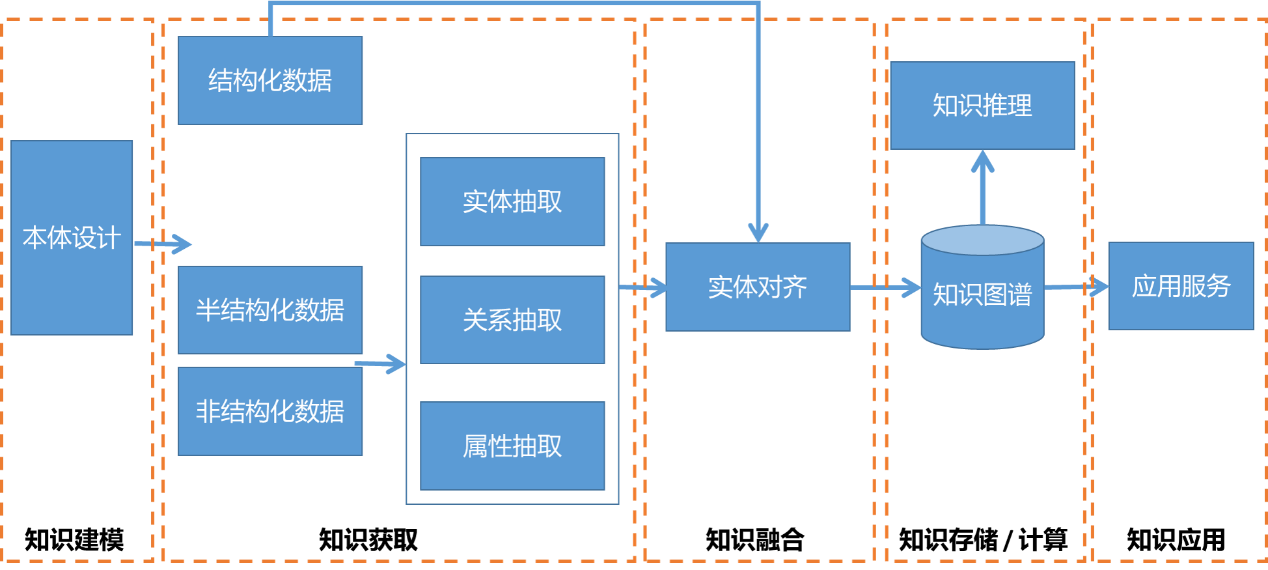
-
在知识建模阶段,需要按照业务需求完成本体设计。
-
在知识获取阶段,知识获取来源可以是结构化数据、半结构化数据或非结构化数据。其中,对半结构化和非结构化的数据需要经过实体抽取、关系抽取以及属性抽取等处理流程。
-
在知识融合阶段,主要解决的问题是实体对齐。
-
在知识存储/计算阶段,知识图谱通常存储在图数据库中,并通过知识表示学习完成进一步的知识推理。
-
在知识应用阶段,上层应用依赖于知识图谱的底层支持。
3.2 技术要点
由上图可知:实体抽取、关系抽取、属性抽取和实体对齐是构建知识图谱的关键环节。由于关系可以看作是一种特殊的属性,关系抽取和属性抽取可归为一类,因此构建知识图谱的技术要点主要有三个:命名实体识别(Named Entity Recognition)、关系抽取(Relation Extraction)、以及实体对齐(Entity Matching)。下面分别介绍这三个技术要点的目标和实现方法。
3.2.1 命名实体识别
命名实体识别是自然语言处理中的一项基本任务,目标是从文本中识别出人们关注的实体类型。如下图24,命名实体一般指的是文本中具有特定意义或者指代性强的实体,通常包括人名、地名、组织机构名、日期时间、专有名词等,在业务需要下也包括人们关注的特定领域内的实体。
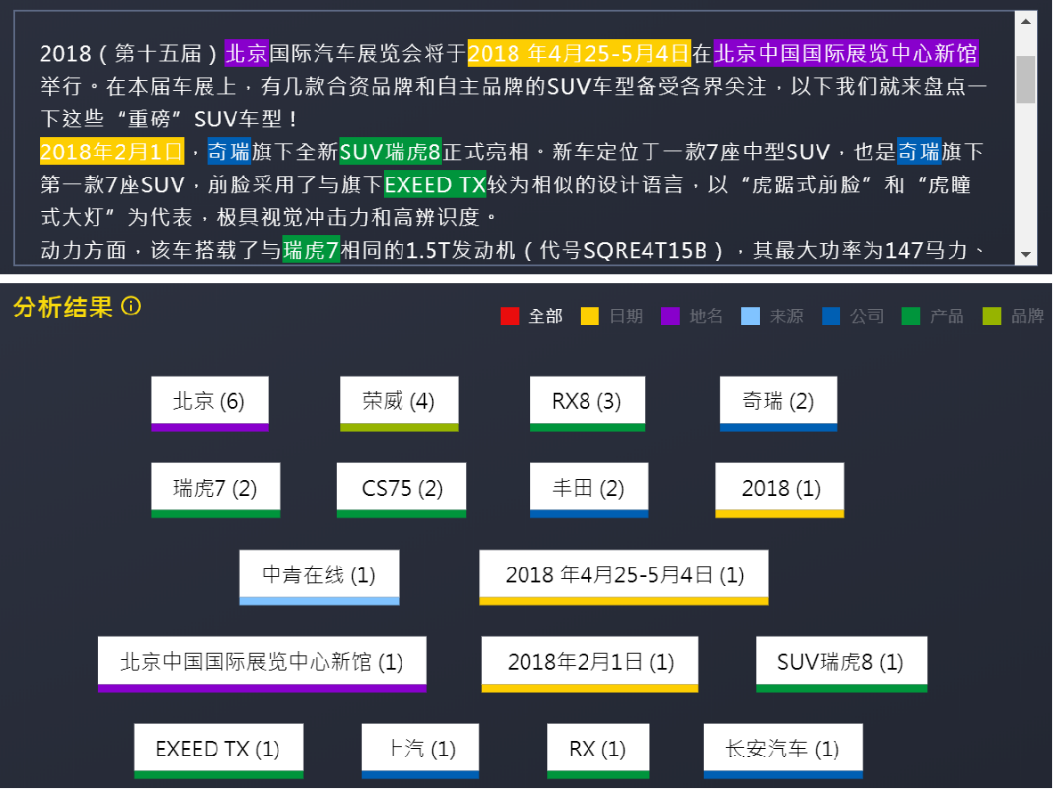
早期的命名实体识别方法多基于规则和字典,后来逐渐出现了基于传统机器学习的方法和基于深度学习的方法。
在基于传统机器学习的方法中,命名实体识别被看作是序列标注问题:首先利用大规模语料学习标注模型,然后对句子的各个位置进行标注,如生成式模型HMM、判别式模型CRF等。但这些方法存在的问题是严重依赖手工特征,并且需要引入外部资源。
随着硬件计算能力的发展以及词分布式表示技术的提出,基于深度学习的方法逐渐兴起。目前比较主流的命名实体识别方法是BiLSTM-CRF模型18,其模型架构如下图,主要包括:Embedding层(主要有词向量、字向量和一些额外特征),BiLSTM层,以及最后的CRF层。
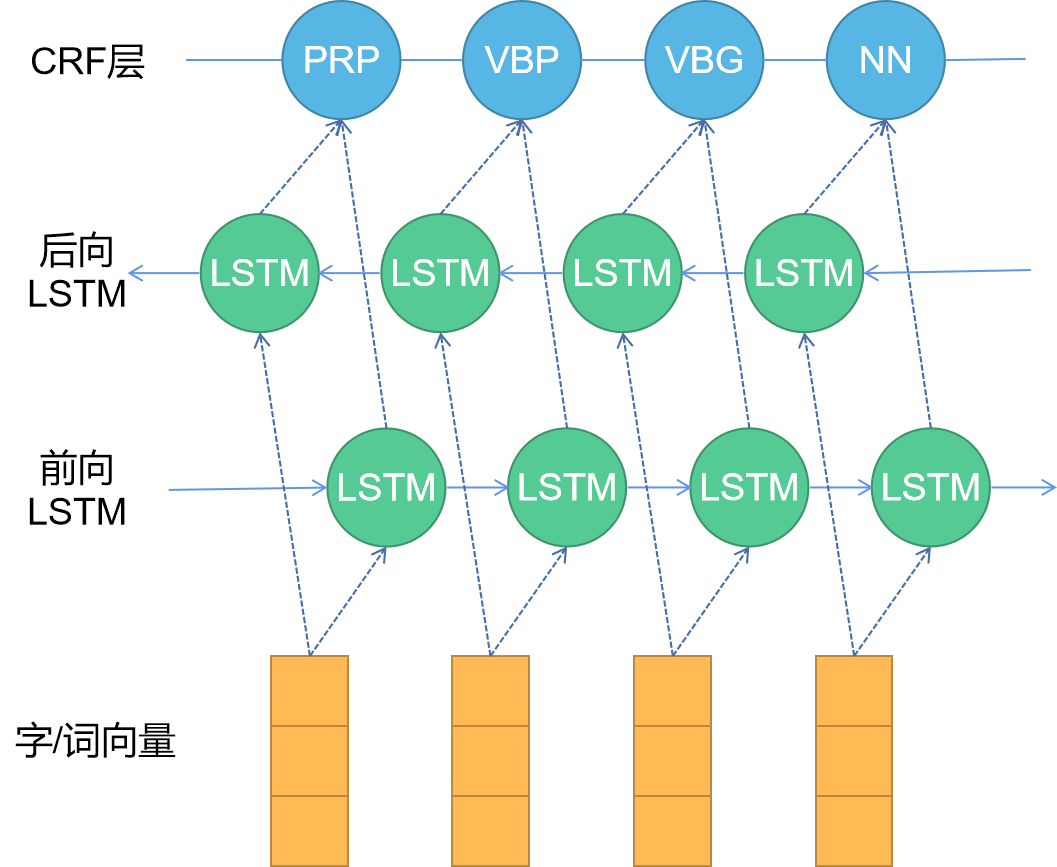
其中,BiLSTM可以捕捉上下文的语义信息,只用BiLSTM也可以完成命名实体识别任务,处理流程为:首先将每个token映射到低维空间中成为稠密的嵌入表示,随后将句子的嵌入表示输入到BiLSTM中,用神经网络自动提取特征,随后用softmax来预测每个token的标签。
但这种方法的缺点是对每个token打标签的过程是独立的,不能直接利用上文已经预测的标签(只能靠隐含状态传递上文信息),从而导致预测出的标签序列可能是无效的,例如标签I-PER(PER实体的中间部分)后面不可能紧跟着B-PER(PER实体的开始部分),而softmax不会利用到这个信息。
为了避免预测出的标签序列无效,在上图中,BiLSTM的输出会接入CRF层来做句子级别的标签预测。CRF层使得标注过程不再是对各个token独立分类,能够给最终的预测标签添加一些约束以确保其合理有效。
实验结果表明:BiLSTM-CRF模型的效果已经达到或者超过了基于丰富特征的CRF模型。在特征方面,该模型是一个端到端的模型,无需特征工程,使用词向量以及字符向量就可以达到很好的效果。如果有高质量的词典特征,模型效果能够获得进一步提高。
3.2.2 关系抽取
关系抽取的目标是从给定的文本中抽取实体之间的语义关系。如下图25,关系抽取技术可以从一段新闻文本中抽取出公司实体之间的子公司关系、人物实体之间的好友关系、以及人物与公司之间的任职关系等。
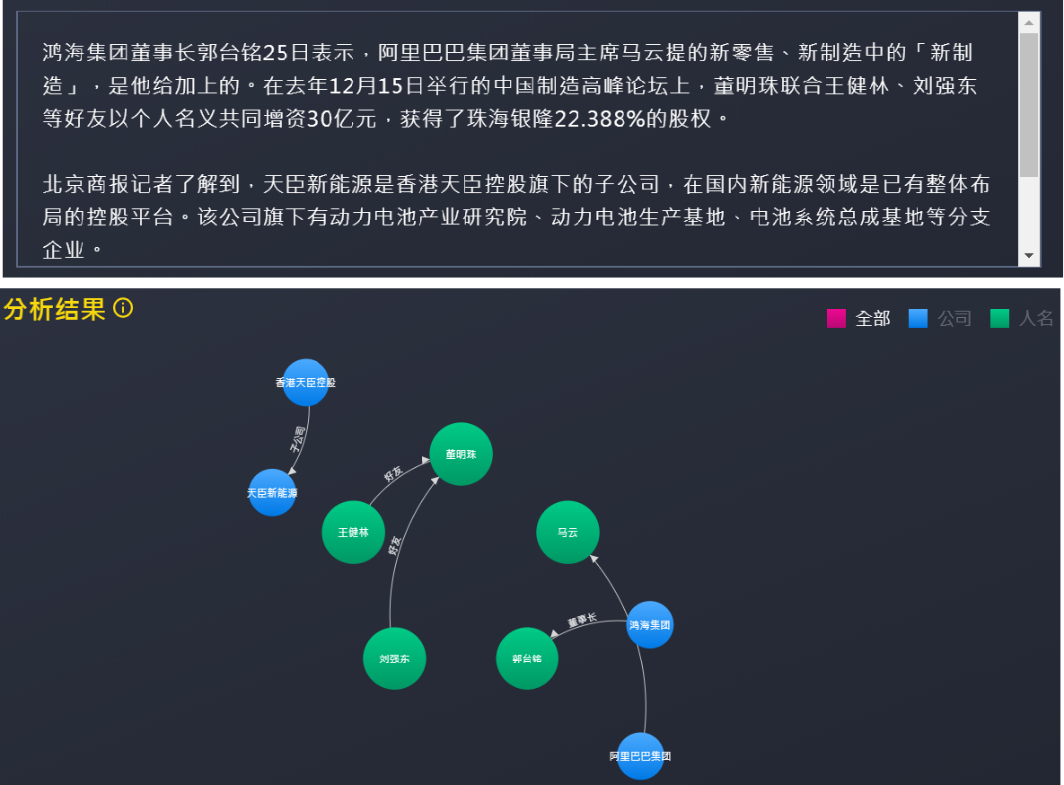
现有的关系抽取方法主要有两种:流水线模型(Pipeline Model)和联合模型(Joint Model)。
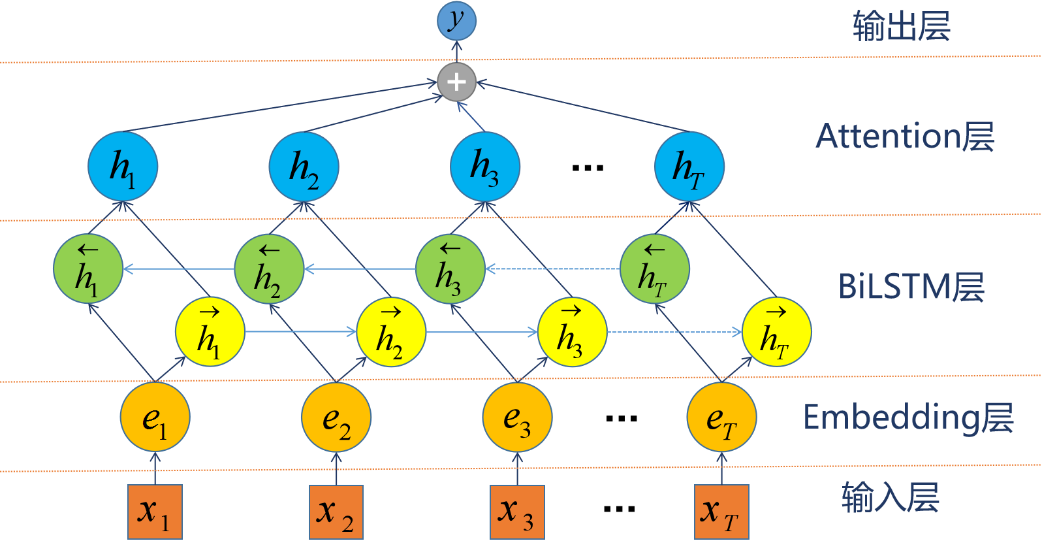
流水线模型是将关系抽取任务分两步处理,即先进行命名实体识别,然后对识别出的实体两两组合,再进行关系分类。常用的关系分类模型例如Att-BiLSTM19,其模型架构如下图。该模型使用BiLSTM克服长距离依赖,并引入注意力机制关注重点信息,避免了传统方法复杂的特征设计工作。
| 模型 | 缺陷 |
|---|---|
| SVM | 手工构造特征,并引入了外部语料库的词汇特征 |
| CNN | 模型自身不适于学习长距离的语义信息 |
| RNN | 由于梯度消失问题,结合上下文的范围有限 |
| SDP-LSTM | 利用两个实体之间的最短依赖路径(SDP) |
| BiLSTM | 利用NLP工具和词汇资源来提取 POS、NER、dependency parse 和 hypernym feature,特征设计复杂 |
流水线模型可以灵活地选取命名实体识别模型与关系分类模型,但在处理过程中存在如下缺点:
1)存在误差传递问题,即命名实体识别模型的准确率会影响整体模型的效果;
2)割裂了实体抽取与关系抽取两个任务的内在联系,忽略了两个任务之间的有用信息,例如已知某两个实体之间存在Country-President关系,那么前一个实体必然属于Location类型,后一个实体必然属于Person类型,流水线模型无法利用这种信息;
3)信息冗余导致效率低,由于对识别出的实体进行两两组合,然后再进行关系分类,那些没有关系的实体对属于冗余信息,使得效率降低。
为克服流水线模型的上述问题,研究者提出联合模型,旨在将实体和关系的抽取同时进行,直接抽取得出实体关系三元组。但这种方法的模型结构相对复杂,在实际应用中不一定能取得更优的效果。
3.2.3 实体对齐
实体对齐的目标是判断不同数据源指称的实体是否对应现实世界中的同一个实体,又称之为“实体消歧”、“实体消解”或“实体匹配”。例如:当两个数据源融合时,一个数据源中有实体“John Smith”,另一个数据源中有实体“J. Smith”,实体对齐要解决的问题就是从数据中寻找证据,从而判断“John Smith”与“J. Smith”是否对应现实世界中的同一个人。
实体对齐的方法大致可分为两类:成对实体对齐(Pair-wise Entity Matching)与集体实体对齐(Collective Entity Matching)。成对实体对齐根据两个实体成对属性之间的相似性判断实体是否匹配,但这种方法忽略了实体之间的关系对匹配决策的影响,因而准确率不高。集体实体对齐考虑了实体之间的关系,但是可以同时处理的实体数量有限,可扩展性差。
因此,有研究者提出了一种基于马尔科夫逻辑网的大规模集体实体对齐框架20,如下图。该框架主要分为三个步骤:1) 将实体匹配器建模为黑盒;2) 将实体集合划分成不同的邻域(所有邻域的并集覆盖全部实体和关系),并在每个邻域上运行实体匹配器的实例;3) 在实体匹配器实例之间使用消息传递机制。
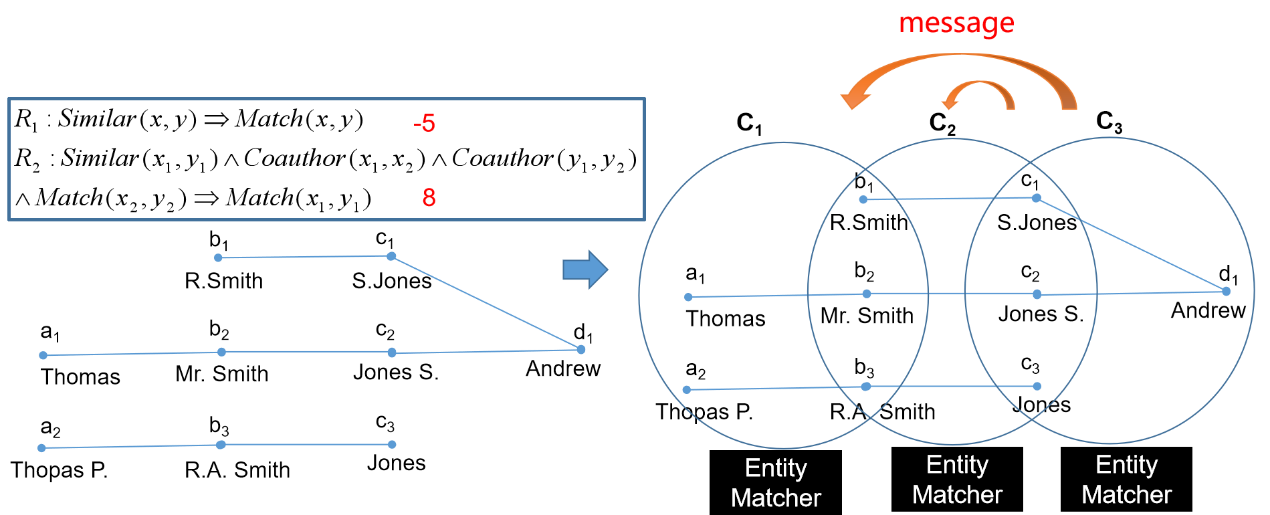
上述三个步骤环环相扣,其中步骤1)满足了框架的通用性,步骤2)实现了集体实体对齐的可扩展性及可并行化,步骤3)保证了实体对齐的准确性和完整性。实验结果显示:该框架在准确率、召回率及运行时间方面均取得了较好的性能。
4. 知识图谱可以用于哪些金融场景(Where)
在对知识图谱是什么、为什么构建知识图谱、怎样构建知识图谱有一定了解后,下面我们探讨知识图谱可以用于哪些金融场景。本节主要介绍知识图谱在风控、营销以及客服三类金融场景中的应用。
4.1 风控类应用
知识图谱的风控类应用23包括反欺诈、失联客户管理以及企业风险预测等。
4.1.1 反欺诈
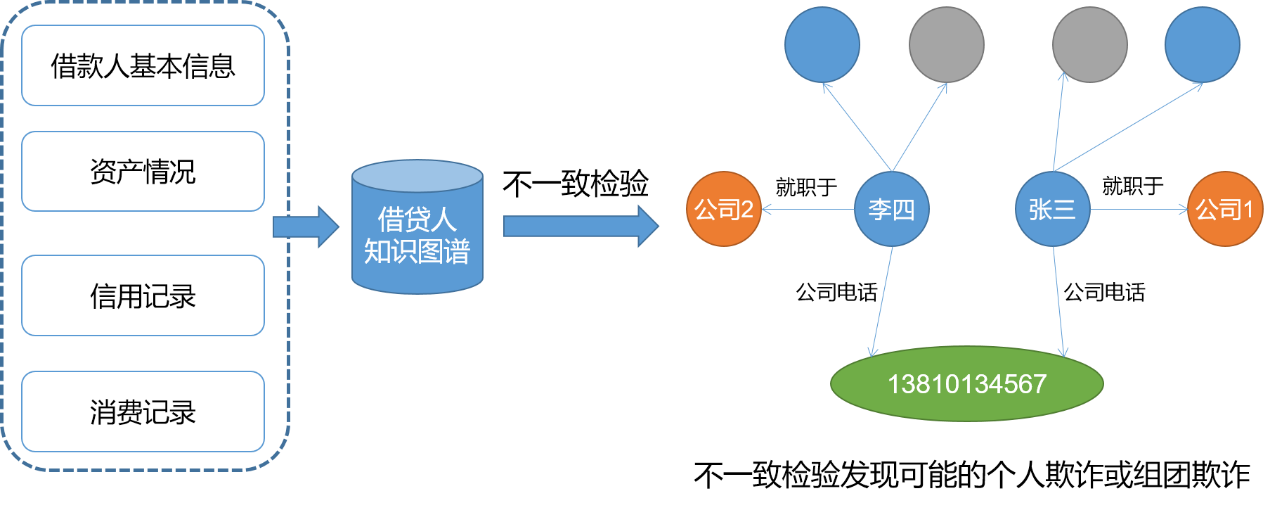
以网络借贷为例,网络借贷公司可以利用借款人基本信息、资产情况、信用记录以及消费记录等信息,构建借贷人知识图谱。在借贷人知识图谱上进行不一致检验,可以发现可能的个人欺诈或组团欺诈。如下图,张三就职于公司1,李四就职于公司2,公司1与公司2不是同一个,而两人却留了相同的公司电话,这就产生了不一致,说明可能存在欺诈风险。
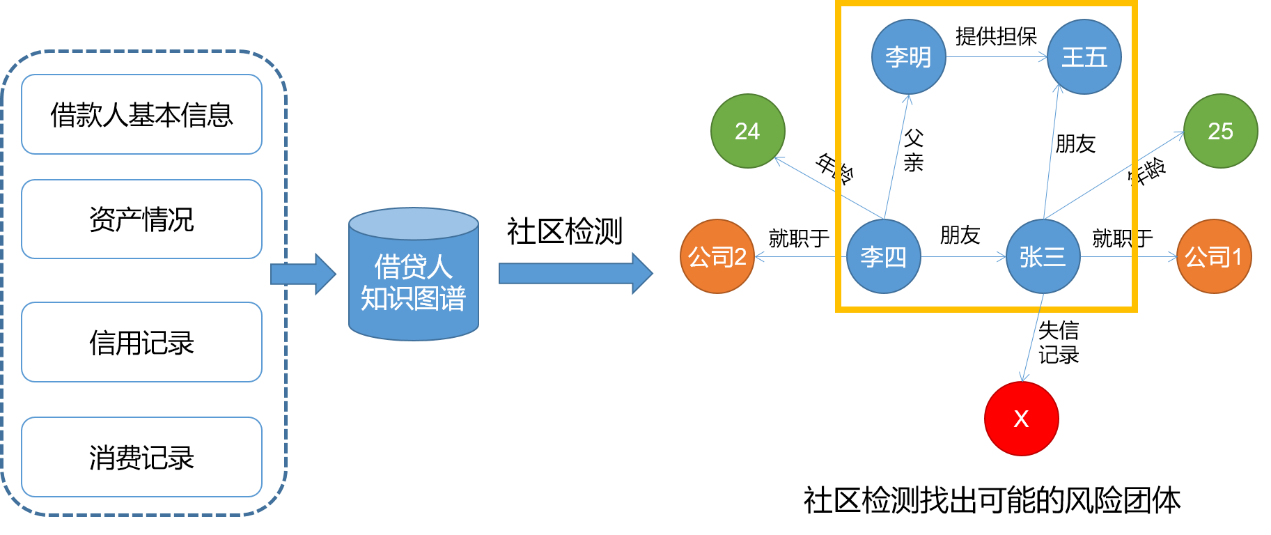
另外,在借贷人知识图谱上进行社区检测,可以找出可能的风险团体。如下图,在借贷人知识图谱中,李四与张三是朋友关系,张三与王五是朋友关系,李四的父亲李明为王五提供了担保,因此这四个人构成了强连通图,属于一个社区。如果在这个社区中,张三存在着失信记录,那么这四个人构成的团体也可能存在着失信风险。
4.1.2 失联客户管理
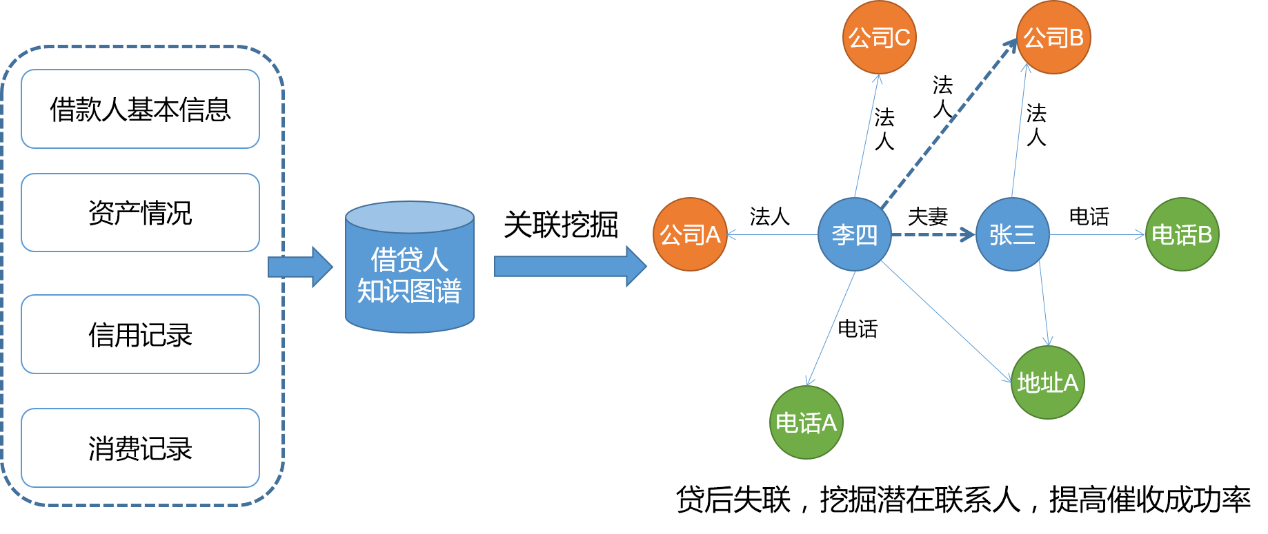
在网络借贷中,反欺诈属于贷前环节,失联客户管理则属于贷后环节。在贷后失联客户管理的问题上,利用知识图谱可以挖掘失联客户的潜在联系人,从而提高催收的成功率。如下图,已知公司B的法人张三贷后失联。从知识图谱中挖掘出李四曾经是公司B的法人,且李四与张三曾经存在夫妻关系,因此推断出李四为张三的潜在联系人,可以尝试通过李四联系张三。
4.1.3 企业风险预测
利用丰富多维度的企业公开信息可以构建企业知识图谱1。企业知识图谱主要由企业、人物、专利等实体构成,关注企业与人物之间任职及股权关系、专利与企业人物的所属权关系等。如下图,企查查26立足于企业征信,通过深度学习、特征抽取以及知识图谱技术对相关信息进行整合,并向用户提供数据信息。
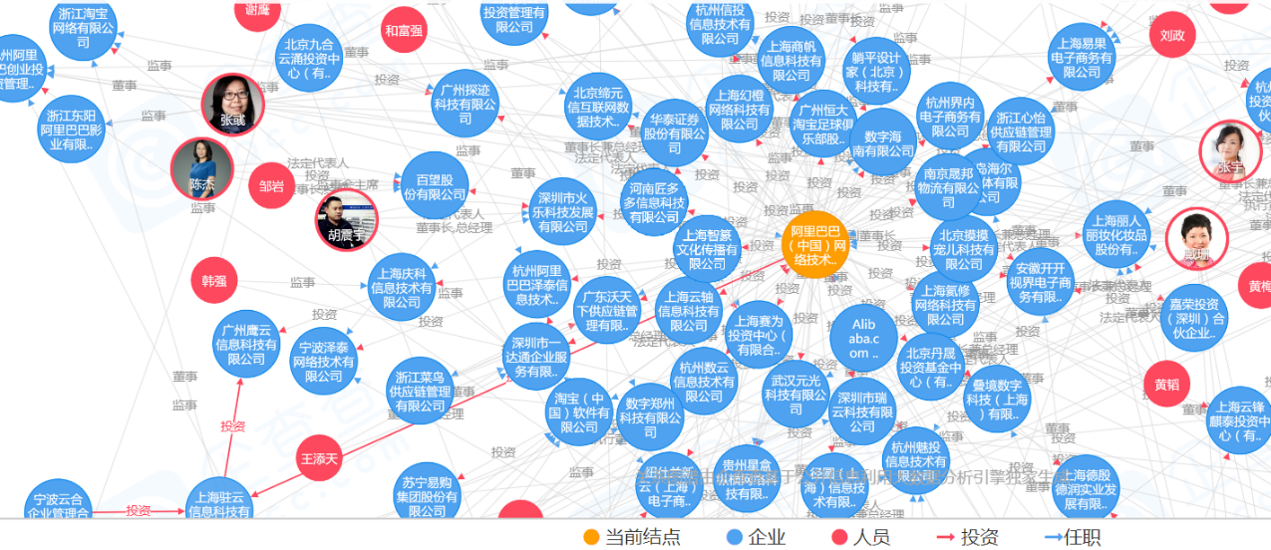
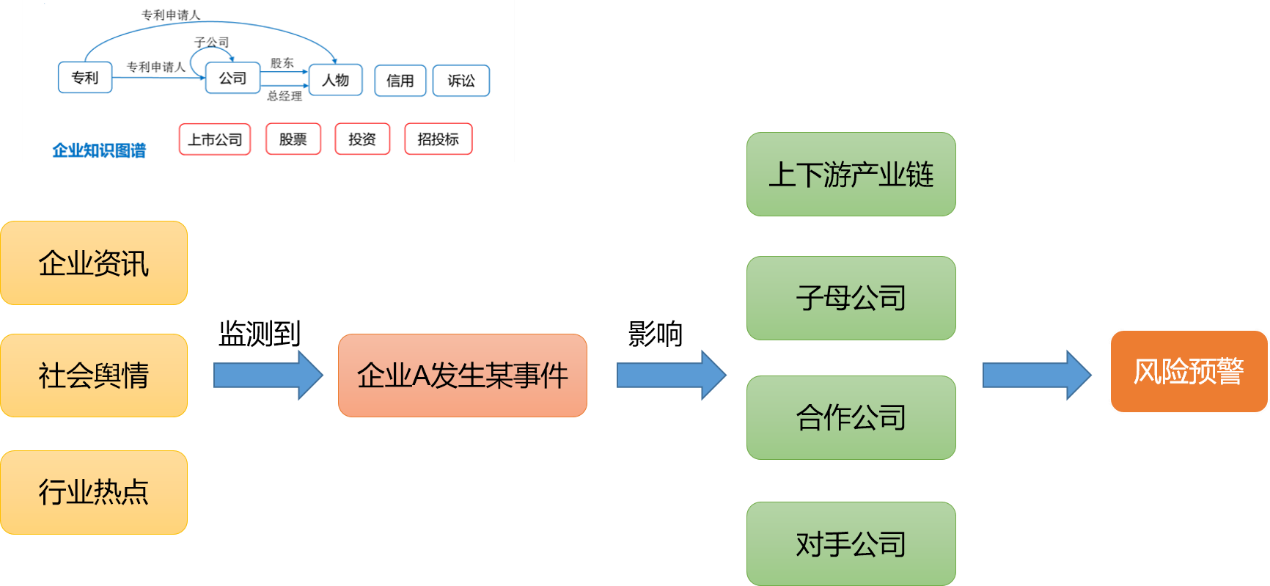
上述企业知识图谱可以辅助完成企业风险预测,流程如下图所示:首先从企业资讯、社会舆情以及行业热点中监测到企业A发生某事件;然后在企业知识图谱中,通过企业关联分析找出企业A的上下游产业链、子母公司、合作公司以及对手公司等,分析该事件对这些相关企业的影响,进而进行风险预警。
4.2 营销类应用
知识图谱的营销类应用主要表现为个性化推荐,如文献21针对证券公司向用户推荐金融新闻以吸引投资特定股票的场景,提出了一种如下图所示的基于知识图谱及图嵌入的金融新闻推荐框架,以期克服金融新闻推荐的难点:1)金融新闻涉及面广,新闻包含与公司、股票相关的外部知识;2)读者兴趣难刻画,金融新闻的读者通常同时对多个特定的公司、股票和行业感兴趣;3)金融新闻的时效性强,存在在线更新问题。
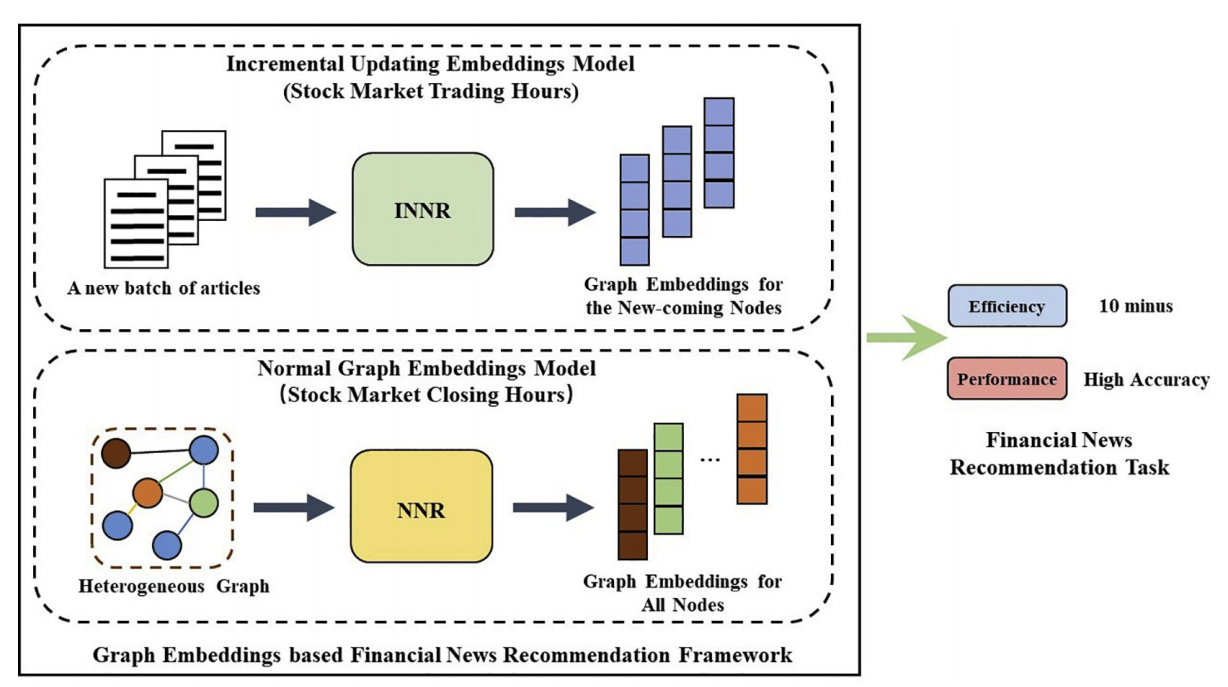
该框架主要分为两部分:一是基于图嵌入的新闻推荐模型(Node2vec-based News Recommendation, NNR),二是增量更新模型(Incremental NNR, INNR)。
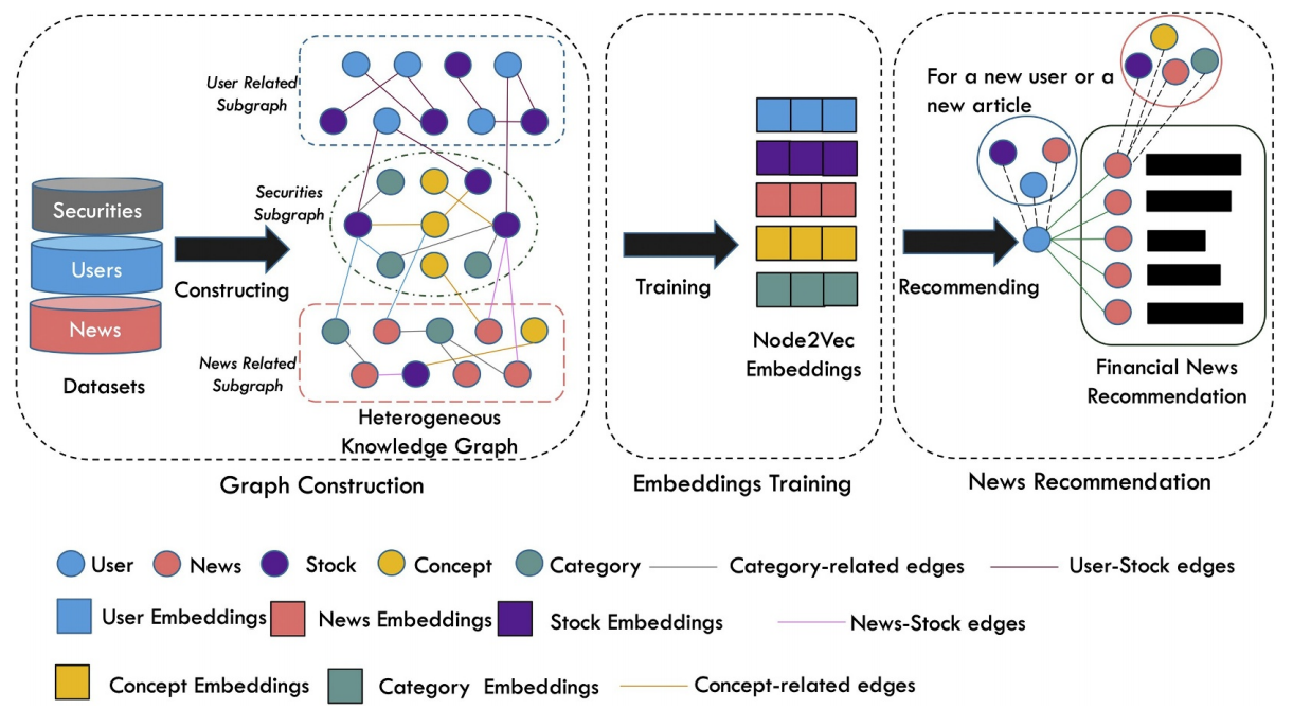
NNR模型框架如下图所示:在图构建阶段,首先构建证券子图、用户子图及新闻子图,然后将三个子图连接起来构成知识图谱;在嵌入训练阶段,使用Node2Vec训练图嵌入表示(也可换用其他的图嵌入算法);在新闻推荐阶段,计算用户嵌入与新闻嵌入的余弦相似度,推荐相似度最高的前k条新闻。
INNR模型框架如下图所示。由于金融新闻在线更新,训练全部千亿级别实体的图嵌入计算代价大,因此INNR选择实体较少发生改变的证券子图作为核心图,只训练核心图的嵌入表示。然后,基于核心图嵌入,INNR使用多种策略来表示新用户或者新的新闻,从而解决用户冷启动及新闻冷启动的问题。
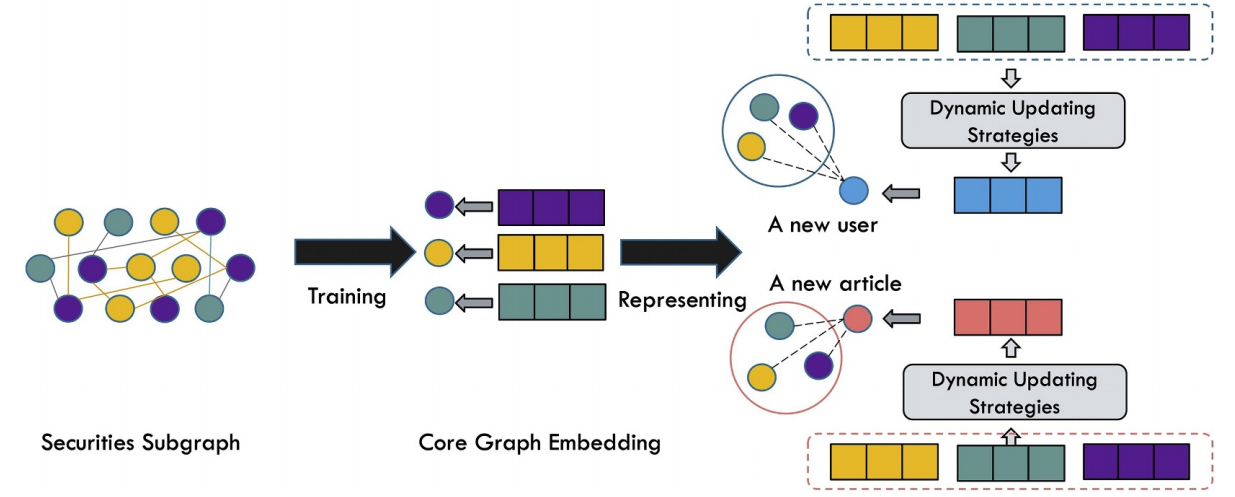
以上应用知识图谱的金融新闻推荐框架,将基于node2vec的推荐方法与增量更新方法结合,可以较好地平衡推荐效率和推荐准确度。
4.3 客服类应用
知识图谱的客服类应用主要表现为智能问答。基于文档的问答是智能问答的一个场景,系统面临的挑战则在于需要在包含多实体和关系的情况下直接应答。这个问题在需要解决基于多文档应答的情况下尤为显著。基于知识图谱的问答系统可能会给出较好的答案,但仍会受限于图谱固有的不完整性和延时性。
为此,支付宝AI工程师提出了QUEST22,一种能够基于即时文本来源,通过计算不同文档的部分结果相似性直接回答复杂问题的方法。QUEST用节点和带权重的边构建了一个带噪声的类知识图谱,其由动态检索的实体名称和关系短语组成。这个类知识图谱又用实体类型和语义对齐进行了扩充,然后用Group Steiner Tree算法计算最佳答案。这种方法是无监督的,不存在训练数据瓶颈,从而能够应对在用户问题当中快速变化的特定主题和表达风格。实验结果表明:QUEST在处理复杂问题时的效果远超目前的最优基线系统。
5. 总结与展望
本文介绍了知识图谱的技术背景及其在金融场景中的应用。其风控类应用主要有反欺诈、失联客户管理以及企业风险预测,营销类应用主要表现为个性化推荐,客服类应用主要表现为智能问答。其他类的应用诸如智能投顾、智能投研等,在此不一一阐述。未来将会出现更多应用形态,如基于知识图谱的智能文本编制,通过知识图谱将行业中的业务知识与文档相结合,在文档编制过程中,进行实时的智能提示、知识校验、知识生产等,辅助文档编制。
总而言之,知识图谱在金融领域大有可为,但不可忽视的是,知识图谱的全面落地仍然面临诸多挑战,比如:领域知识复杂难以集成,数据的深层关系难抽取,生成的策略仅能辅助决策等。随着知识图谱构建技术的不断发展和对应用场景的持续探索,相信知识图谱能够在金融领域进一步解放生产力,助力业务转型。
-
Nickel M, Tresp V, Kriegel H P. A Three-Way Model for Collective Learning on Multi-Relational Data[C]. Proceedings of the 28th International Conference on Machine Learning, 2011: 809-816. ↩
-
Jenatton R, Roux N L, Bordes A, et al. A Latent Factor Model for Highly Multi-Relational Data[C]. Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems, 2012: 3167-3175. ↩
-
Socher R, Chen D, Manning C D, et al. Reasoning with Neural Tensor Networks for Knowledge Base Completion[C]. Proceedings of the 26th Advances in Neural Information Processing Systems: the 27th Annual Conference on Neural Information Processing Systems, 2013: 926-934. ↩
-
Bordes A, Usunier N, Garcia-Duran A, et al. Translating Embeddings for Modeling Multi-Relational Data[C]. Proceedings of the Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems, 2013: 2787-2795. ↩
-
Wang Z, Zhang J, Feng J, et al. Knowledge Graph Embedding by Translating on Hyperplanes[C]. Proceedings of the 28th AAAI Conference on Artificial Intelligence, 2014: 1112-1119. ↩
-
Bollacker K, Evans C, Paritosh P, et al. Freebase: A Collaboratively Created Graph Database for Structuring Human Knowledge[C]. International Conference on Management of Data, 2008: 1247-1250. ↩
-
Suchanek F M, Kasneci G, Weikum G, et al. YAGO: A Large Ontology from Wikipedia and WordNet[J]. Journal of Web Semantics, 2008, 6(3): 203-217. ↩
-
Vrandečić D, Krötzsch M. WikiData: A Free Collaborative Knowledge Base[J]. Communications of the ACM, 2014, 57(10) :75-85. ↩
-
Auer S, Bizer C, Kobilarov G, et al. DBPedia: A Nucleus for a Web of Open Data[C]. Proceedings of the Semantic Web, 6th International Semantic Web Conference, 2nd Asian Semantic Web Conference, 2007: 722-735. ↩
-
Carlson A, Betteridge J, Kisiel B, et al. Toward an Architecture for Never-Ending Language Learning[C]. Proceedings of the 24th AAAI Conference on Artificial Intelligence, 2010:1306-1313. ↩
-
Wu W, Li H, Wang H, et al. Probase: A Probabilistic Taxonomy for Text Understanding[C]. Proceedings of the 39th ACM SIGMOD International Conference on Management of Data, 2012: 481-492. ↩
-
Dong X, Gabrilovich E, Heitz G, et al. Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion[C]. Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2014: 601-610. ↩
-
Belleau F, Nolin M A, Tourigny N, et al. Bio2RDF: Towards a Mashup to Build Bioinformatics Knowledge Systems[J]. Journal of Biomedical Informatics, 2008, 41(5): 706-716. ↩
-
Ashburner M, Ball C A, Blake J A, et al. Gene Ontology: Tool for the Unification of Biology[J]. Nature Genetics, 2000, 25: 25. ↩
-
Kemp C, Tenenbaum J B, Griffiths T L, et al. Learning Systems of Concepts with an Infinite Relational Model[C]. Proceedings of the 21st National Conference on Artificial Intelligence and the 18th Innovative Applications of Artificial Intelligence Conference, 2006: 381-388. ↩
-
Ma X, Hovy E. End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF[C]. Meeting of the Association for Computational Linguistics, 2016: 1064-1074. ↩
-
Zhou P, Shi W, Tian J, et al. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification[C]. Meeting of the Association for Computational Linguistics, 2016: 207-212. ↩
-
Rastogi V, Dalvi N, Garofalakis M, et al. Large-scale Collective Entity Matching[C]. Very Large Data Bases, 2011, 4(4): 208-218. ↩
-
Ren J, Long J, Xu Z, et al. Financial News Recommendation Based on Graph Embeddings[J]. Decision Support Systems, 2019. ↩
-
Lu X, Pramanik S, Roy R S, et al. Answering Complex Questions by Joining Multi-Document Evidence with Quasi Knowledge Graphs[C]. International ACM SIGIR Conference on Research and Development in Information Retrieval, 2019: 105-114. ↩
-
https://www.wisers.ai/zh-cn/browse/named-entity-recognition/demo/ ↩
-
https://www.wisers.ai/zh-cn/browse/relation-extraction/demo/ ↩